
Elon Musk’s X, formerly known as Twitter, is the hub of all international news and conversation, and for good reason. The platform allows anyone to post content without censorship and opens channels for discussion and debate. However, due to the sensitive nature of today’s geopolitical world, some of these posts can include explicit content that isn’t suitable for everyone. Fortunately, the platform does limit visibility of such content by adding a “This media may contain sensitive material” or “Potentially sensitive content” banner before it. You can also change settings to either bypass this default message or disable sensitive content altogether. This article teaches you how.
How To View Sensitive Content on X?
As mentioned, X lets you change the default setting for sensitive content. On Android/iOS, the process is super simple. Here’s how:
- Open the X app and click the profile button in the top left corner.
- Scroll down to Settings & Support, then click Settings & Privacy.
- Tap Privacy and safety, then navigate to the Content you see section.
- Click Sensitive Media.
- Turn on the options for Graphic violence, Adult content, and Other.
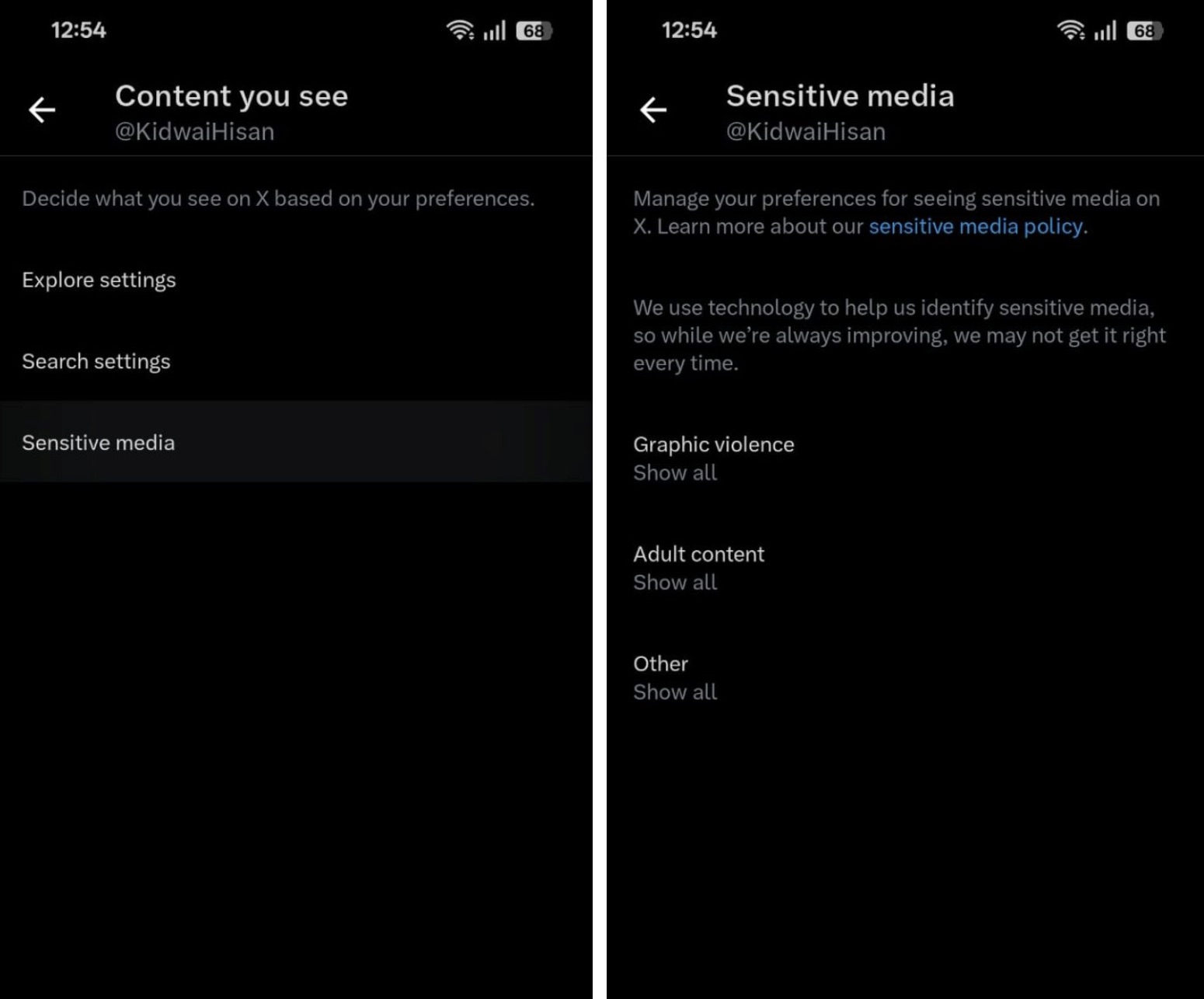
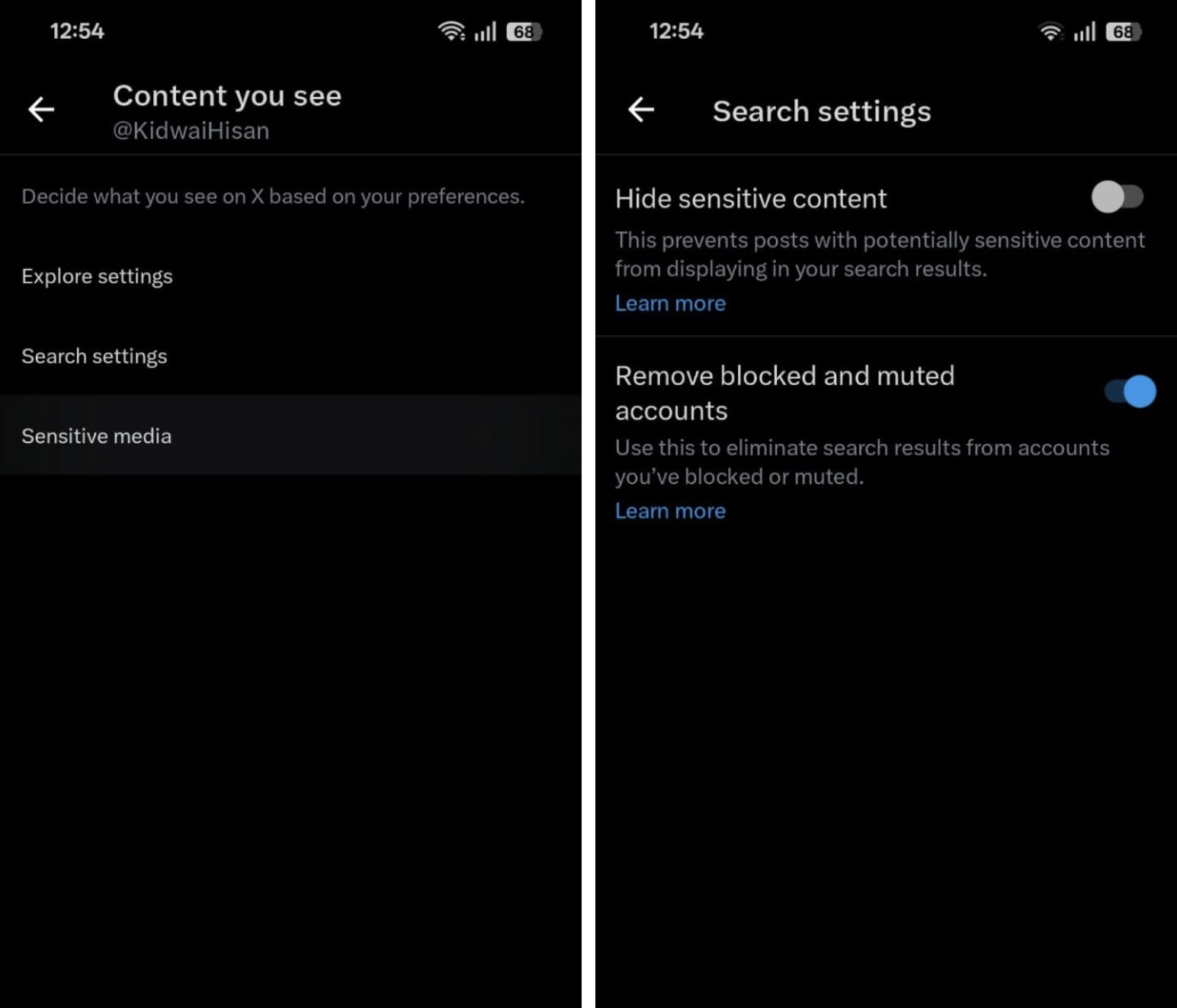
- Head back to Search Settings.
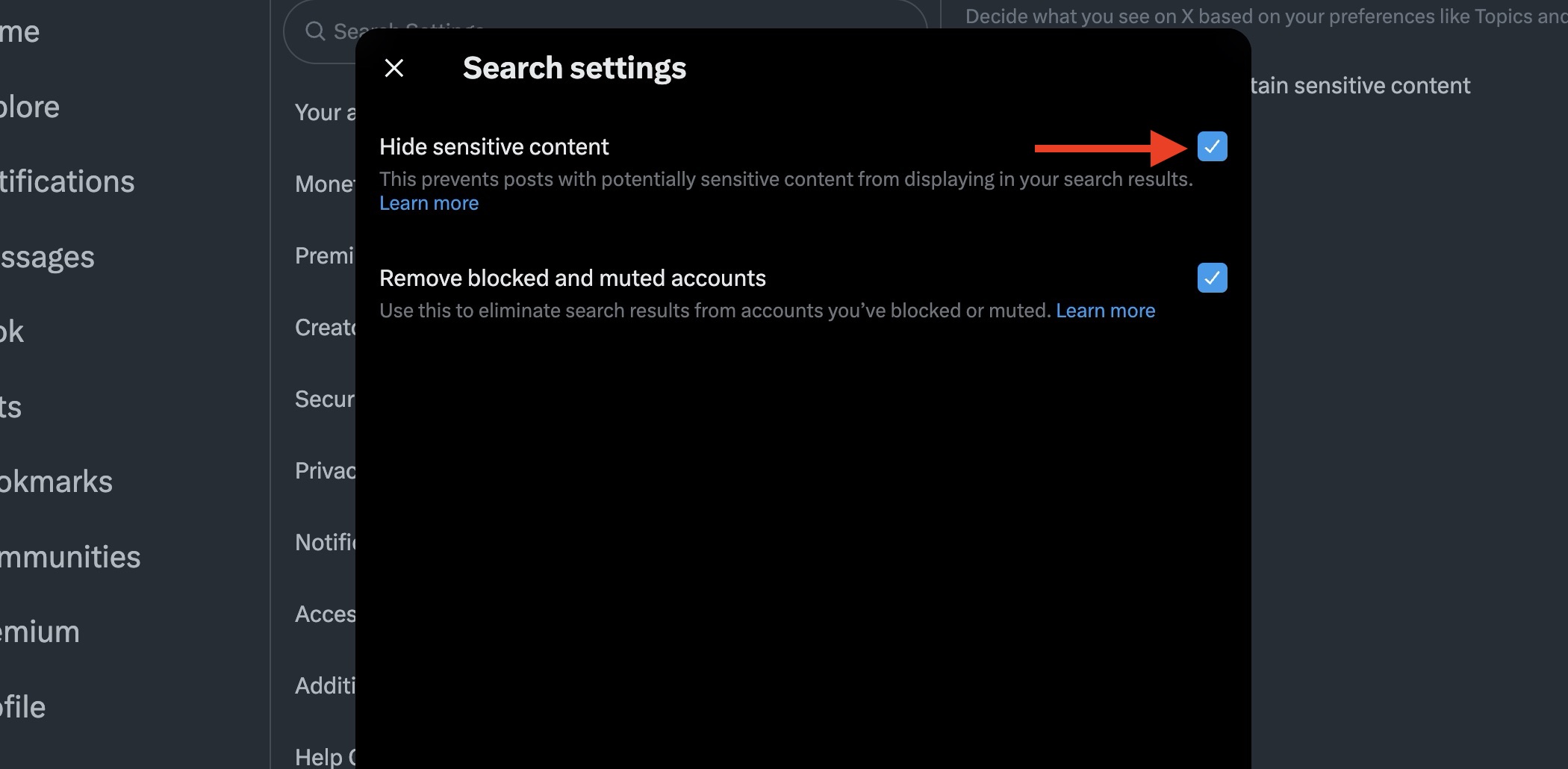
- Disable the toggle for Hide Sensitive Content in the search results.
View Sensitive Content on the X Website
- Head to X.com and log in to your account.
- Click More, then head to Settings & Privacy.
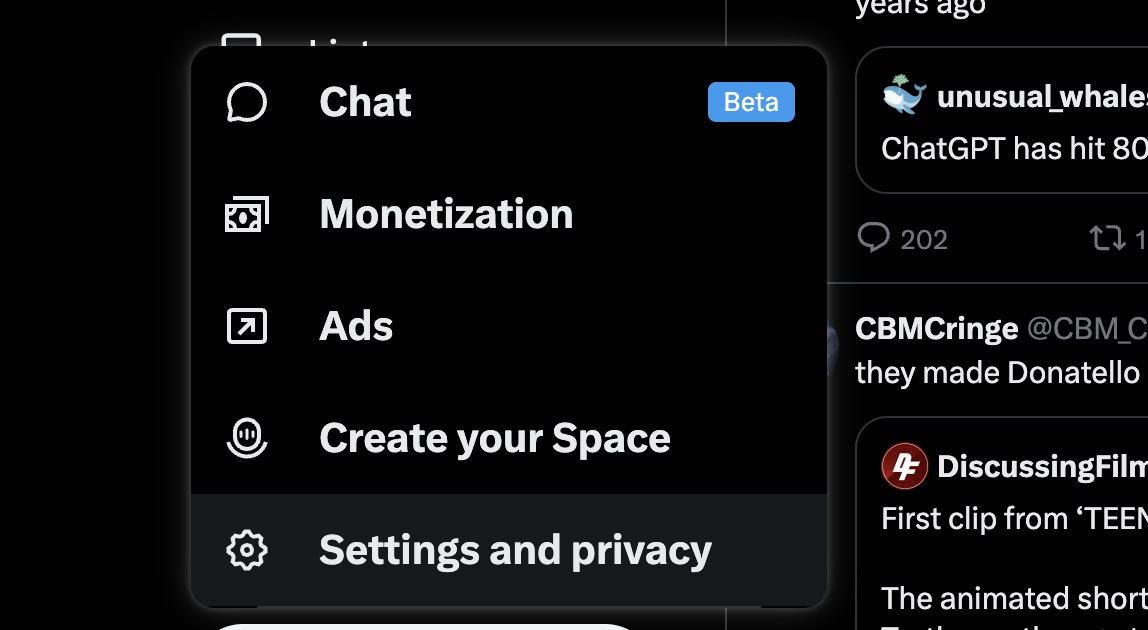
- Tap Privacy and Safety.
- Select Content you see.
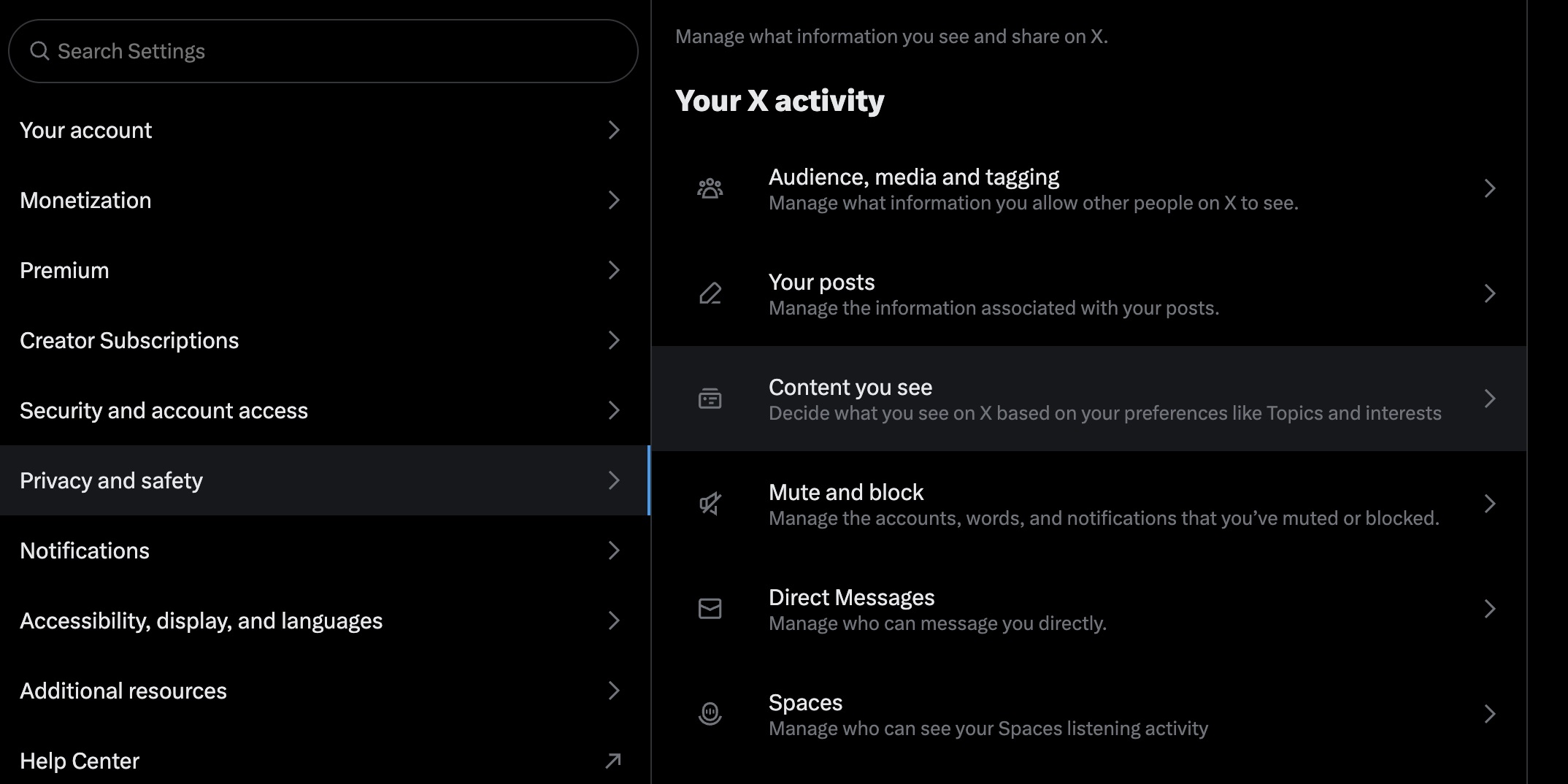
- Check the box labeled Display media that may contain sensitive content.
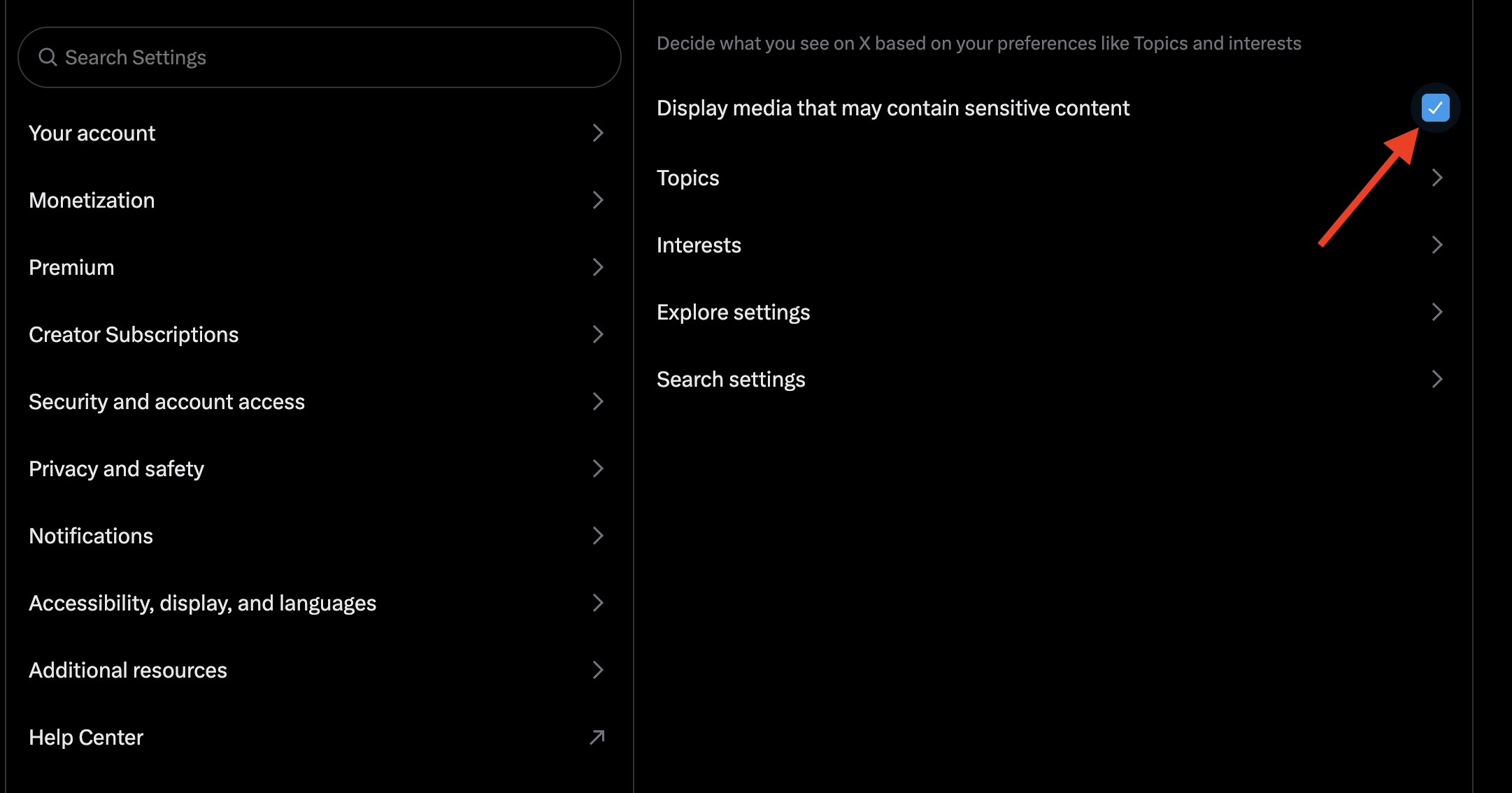
- Navigate to the Search Settings section.
- Uncheck the Hide Sensitive Content box.
What’s Sensitive Content on X?
As mentioned, X allows anyone to post content, news, or images without censorship. In addition to the basic, nudity, and sexual behavior posts, sensitive content also comprises graphic violence, gratuitous gore, and animal abuse content. Such content, however important, isn’t suitable for everyone and requires a badge to indicate its intended audience.
X actually allows consensually produced adult content as long as it’s already labelled accurately by the uploader. To do this, return to the Settings and Privacy tab and navigate to My Posts. There, turn on Mark media you post as having material that may be sensitive. You are not allowed to upload sensitive content on profile images or headers, though. By default, children under 18 years old are prohibited from viewing any sensitive content on the platform.
Source link
#Turn #Sensitive #Content #Blurring
 pieces of newly developed interchangeable hands, including: One (1) pair of fists One (1) pair of relaxed hands One (1) pair of magical book-holding/mystic power-using hands One (1) pair of translucent green with black krackle mystic power effect hands Costume: One (1) set of newly tailored Doctor Doom armored suit, including: One (1) dark green colored hooded cloak (bendable wire embedded) with magnetically detachable clasps and a metal material chain One (1) dark green colored tunic with square grid textured patterns One (1) dark green colored undersuit One (1) pair of silver colored pauldrons One (1) pair of silver colored chainmail sleeves One (1) pair of silver colored gauntlets One (1) fabric wrap (attached to the left arm) One (1) black colored belt with a silver colored rectangular buckle One (1) pair of dark green colored pants One (1) pair of silver colored poleyns One (1) pair of silver colored greaves One (1) pair of silver colored sabatons Accessories: One (1) magical book (inspired by concept art) One (1) pair of translucent green colored flame effect (attachable to the hands) Specially designed figure stand with Avengers: Doomsday logo and character nameplate It’s so long it has sub-bullets! And that’s just for the “Collector Version,” which is actually the base model and will set you back 5. The Ultimate Version, which includes a “specially designed Sentinel’s hand-themed diorama figure base with LED light-up function” and “one mystery accessory,” can be yours for 0. And if you want Doom’s throne to complete your display, that’ll cost another 0. You can pre-order the Doctor Doom 1/6 Scale Collectible Figure here, and Doom’s Throne here. The rest of the Hot Toys and Sideshow Avengers: Doomsday line is equally impressive, with Professor X, Magneto (5 Collector, 0 Deluxe), Cyclops (5 Standard, 0 Deluxe), Beast, Gambit (5 Standard, 5 Deluxe, no I will not make a snarky comment about why Gambit’s Deluxe figure is less expensive than the rest), and a Sentinel. Doctor Doom, his Throne, Magneto, Cyclops, and Gambit are all available for pre-order now, while you can sign up for updates on Professor X, Beast, and the Sentinel. Check out images of all of them below. Hasbro is also launching a Marvel Legends figure collection for Avengers: Doomsday. You can check out exclusive images of those over at People. Want more io9 news? Check out when to expect the latest Marvel, Star Wars, and Star Trek releases, what’s next for the DC Universe on film and TV, and everything you need to know about the future of Doctor Who. #Avengers #Doomsday #Hot #Toys #Figures #Give #Doctor #DoomAvengers: Doomsday,Hasbro,Hasbro Marvel Legends,Hot Toys,San Diego Comic-Con,Sideshow")
 pieces of newly developed interchangeable hands, including: One (1) pair of fists One (1) pair of relaxed hands One (1) pair of magical book-holding/mystic power-using hands One (1) pair of translucent green with black krackle mystic power effect hands Costume: One (1) set of newly tailored Doctor Doom armored suit, including: One (1) dark green colored hooded cloak (bendable wire embedded) with magnetically detachable clasps and a metal material chain One (1) dark green colored tunic with square grid textured patterns One (1) dark green colored undersuit One (1) pair of silver colored pauldrons One (1) pair of silver colored chainmail sleeves One (1) pair of silver colored gauntlets One (1) fabric wrap (attached to the left arm) One (1) black colored belt with a silver colored rectangular buckle One (1) pair of dark green colored pants One (1) pair of silver colored poleyns One (1) pair of silver colored greaves One (1) pair of silver colored sabatons Accessories: One (1) magical book (inspired by concept art) One (1) pair of translucent green colored flame effect (attachable to the hands) Specially designed figure stand with Avengers: Doomsday logo and character nameplate It’s so long it has sub-bullets! And that’s just for the “Collector Version,” which is actually the base model and will set you back 5. The Ultimate Version, which includes a “specially designed Sentinel’s hand-themed diorama figure base with LED light-up function” and “one mystery accessory,” can be yours for 0. And if you want Doom’s throne to complete your display, that’ll cost another 0. You can pre-order the Doctor Doom 1/6 Scale Collectible Figure here, and Doom’s Throne here. The rest of the Hot Toys and Sideshow Avengers: Doomsday line is equally impressive, with Professor X, Magneto (5 Collector, 0 Deluxe), Cyclops (5 Standard, 0 Deluxe), Beast, Gambit (5 Standard, 5 Deluxe, no I will not make a snarky comment about why Gambit’s Deluxe figure is less expensive than the rest), and a Sentinel. Doctor Doom, his Throne, Magneto, Cyclops, and Gambit are all available for pre-order now, while you can sign up for updates on Professor X, Beast, and the Sentinel. Check out images of all of them below. Hasbro is also launching a Marvel Legends figure collection for Avengers: Doomsday. You can check out exclusive images of those over at People. Want more io9 news? Check out when to expect the latest Marvel, Star Wars, and Star Trek releases, what’s next for the DC Universe on film and TV, and everything you need to know about the future of Doctor Who. #Avengers #Doomsday #Hot #Toys #Figures #Give #Doctor #DoomAvengers: Doomsday,Hasbro,Hasbro Marvel Legends,Hot Toys,San Diego Comic-Con,Sideshow")
. That said, there are some tricks to getting the best night’s sleep and having a pleasant trip.Don’t inflate your pad with your mouth: For one thing, some of these pads are huge, and it’s just a pain, but also your breath is warm and moist and you’re injecting into nylon, which is a recipe for mildew and mold. This worry may be somewhat overblown—a few people have cut open pads they’ve inflated by mouth for years and found no sign of mold—but considering what a pain it is to do anyway, it seems easier to just avoid it. Most manufacturers include some kind of pump sack these days, which makes quick work of inflating your pad. There are also motorized pumps that only weigh an ounce or two, like the Flextail pump.Don’t over-inflate: Insulated sleeping pads work by putting air and material between you and the cold ground, but that doesn’t mean you need to inflate it until it’s taut. It varies by pad. I generally find that the best method is to inflate it taut, and then start to let out air, lying down to test it until you get to where it feels comfortable. The downside to this method is that your pad isn’t that thick and you’re more likely to bottom out if you let out too much air. I find this isn’t much of an issue for stomach or back sleepers, but if you’re a side sleeper it might take some time to find the sweet spot between comfort and warmth.Carry a patch kit: Most sleeping pads these days include a patch kit. I rarely bring these kits and instead carry a small roll of Tenacious Tape (), which will solve rips and tears in everything from sleeping pads to tents. Make sure to test a small piece of tape on your pad beforehand to make sure the tape sticks, and bring an alcohol wipe to clean the affected area.Women need higher R-value pads: Women generally have lower body mass than men, which means women should add roughly 1 R-value to get the same amount of insulation in the same situation. (I also recommend upping the R-value if you’re a cold sleeper in general.)Sleeping bag ratings assume R5 pads: Most temp ratings you see on sleeping bags are true only if you’re using a sleeping pad with an R-value of 5 or higher (they also assume you’re wearing a base layer). If your pad is less, you will need to adjust your sleeping bag temp rating accordingly. For example, using your 30 degree quilt with a R4 pad will likely leave you cold if you encounter freezing temps. In that situation you’d want to either up the R-value of the pad, or bring a warmer sleeping bag.#Ive #Slept #Countless #Backpacking #Pads #Worth #Carryingshopping,outdoors,buying guides,backpacking")

Post Comment